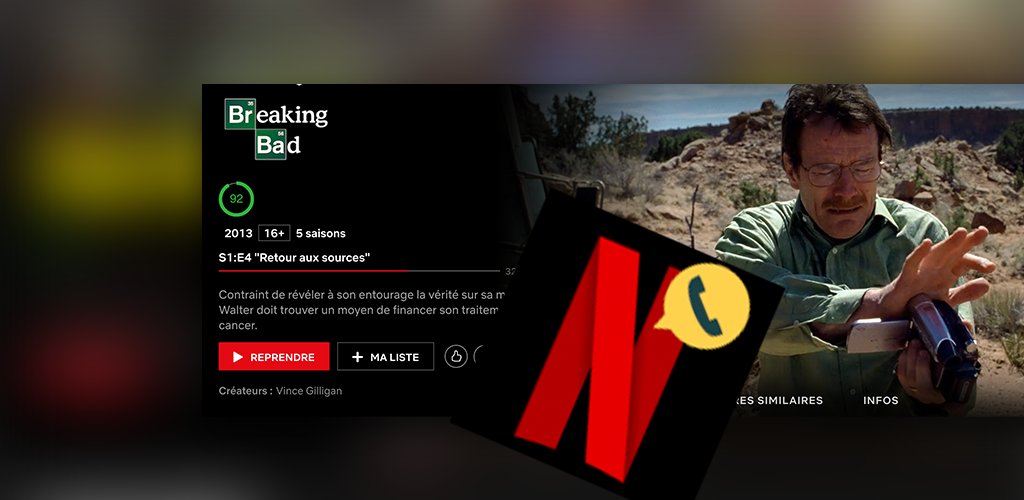
Noteflix: Une extension firefox pour voir les notes Allociné sur Netflix
Comme bon nombre d’entre vous, je profite du confinement pour avancer sur des projets personnels. Jeudi dernier, après avoir passé près de 4h à coder sur un projet personnel en react-native, je me suis dis :
Et si je me mettais une petite série Netflix ?
Ni une, ni deux, j’ouvre Netflix et commence à chercher LA série qui va me tenir en haleine sur les prochains jours.
Problème, il m’arrive souvent de tomber sur des séries un peu naze comme Marianne, cette bouse comiquo-horrifique  .
.
C’est à ce moment précis qu’il me vint à l’esprit une idée de génie
Ça pourrait être pas mal d’avoir un meilleur indicateur de notes des films et séries netflix !
 21h, la décision est prise: Je me lance dans le développement d’une extension firefox pour récupérer les notes allociné afin de les intégrer à Netflix.
21h, la décision est prise: Je me lance dans le développement d’une extension firefox pour récupérer les notes allociné afin de les intégrer à Netflix.
Les premiers balbutiements
Quand on commence un nouveau projet, on a toujours envie de commencer fort, d’utiliser la dernière techno à la mode, de ne pas réfléchir et “pisser du code” vite, très vite !
C’est pourtant tout ce qu’il ne faut pas faire. Le plus dur c’est justement de bien réfléchir aux choix techniques, aux risques, à pondérer chaque technos pour ses avantages et inconvénients etc..
BREF, c’est chiant mais on a souvent pas le choix !
…
SAUF quand tu codes une extension Firefox pour un side project dont tu te contrefous de la dernière techno à la mode puisque de toute facon tu feras au mieux du Typescript transpilé pour aller dans un environement cloisonné. 
Je n’avais donc pas beaucoup de questions à me poser, je savais que j’allais partir sur du Javascript ou au mieux du Typescript et que le code ne serait pas très complexe étant donné que ça serait qu’un simple appel ajax à l’API d’Allociné.
Du moins, c’est ce que je croyais 
J’avais déjà réalisé une petite extension Firefox sans l’avoir publié sur le store de Mozilla, je partais donc avec un léger avantage de ce côté là. Par contre, je n’avais jamais regardé de près comment fonctionne le site d’allociné. Ce n’est pas un site que je regarde régulièrement mais c’est en général le premier que je vais voir quand je recherche une information sur un film ou une série (d’ou mon choix de l’intégrer à Netflix)
J’ai donc commencé ce side-project en me faisant un petit repository GitHub avec un bootstrap d’extension pour juste faire mes premiers crash-tests. Avant de m’attaquer à Netflix, je voulais m’assurer qu’il était possible de récupérer les notes de films/séries depuis l’API d’allocine.
Je pars convaincu, serein, frais comme un gardon, bref j’suis chaud 
J’arrive sur le site d’allociné et je commence à investiguer un peu ce qu’il se passe sur le site:
- F12, onglet réseaux, est ce qu’il y a des call XHR au chargement de la page ? Nope !
- Je regarde les différents input afin de voir si certains marchent en Ajax, bingo ! celui de la barre de recherche fait un call ajax

Voyons un peu ce que ça donne en recherchant Breaking bad:
{
"error":false,
"message":null,
"results":[
{
"entity_type":"series",
"entity_id":"3517",
"gid":"series.series._.3517",
"label":"Breaking Bad",
"facet":"series",
"original_label":"Breaking Bad",
"text_search_data":[
"BrBa"
],
"status":12,
"viewcount":975962,
"irankpopular":41,
"browsable":true,
"last_release":null,
"data":{
"id":3517,
"year":"2008",
"is_program":false,
"poster_path":"\/pictures\/19\/06\/18\/12\/11\/3956503.jpg",
"creator_name":[
"Vince Gilligan"
],
"showrunner_name":[
"Vince Gilligan"
],
"thumbnail":"http:\/\/fr.web.img6.acsta.net\/c_75_100\/pictures\/19\/06\/18\/12\/11\/3956503.jpg"
},
"scores":{
"rating_score":4,
"weekly_rank_score":3,
"all_time_rank_score":5
},
"genres":[
"Drama"
],
"tags":[
"Series.Type.Series",
"Series.Status.Ended",
"Info.Genre.Drama",
"Format.Color.Color"
],
"last_updated_at":"2020-03-27T08:16:53.320000+01:00",
"index":"search_ac_20200408070105",
"type":"search",
"id":"series.series._.3517",
"score":23897.488,
"sponsored":false
}
]
}
On remarque que le format de réponse est assez light, 3 champs dont un qui nous intéresse results, qui contient les objets répondant à notre recherche.
Ces objets peuvent être des films, séries ou des personnalités. C’est déjà une première étape à garder en tête vu qu’on ne voudra que ce qui est films ou séries.
On y trouve aussi un objet scores, intéressant !
{
"scores": {
"rating_score":4,
"weekly_rank_score":3,
"all_time_rank_score":5
}
}
Parfait, je regarde donc à quoi correspondent ces scores, voir si ils correspondent à ce que je recherche (en l’occurence, les notes des spectateurs).
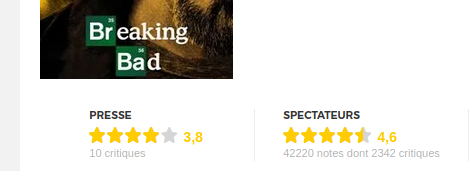
Jeanne  ! Au secours ! D’où proviennent ces scores ? J’ai beau tester avec 2 ou 3 autres films/séries, aucune corrélation n’est envisageable.
! Au secours ! D’où proviennent ces scores ? J’ai beau tester avec 2 ou 3 autres films/séries, aucune corrélation n’est envisageable.
Je continue donc mon investigation en fouinant sur le site mais rien n’y fait, je ne trouve aucune donnée viable via une API. Je décide donc de regarder un peu sur google et je tombe sur le blog d’un certains Gromez qui parle de l’API d’Allociné.
L’article est vieux (2013) mais très intéressant, il parle des différents endpoint qu’il a pu trouver en regardant le comportement de l’app mobile via un analyseur de paquet.
Malheureusement, l’article étant daté, les liens et token fournis le sont aussi. Je décide donc à mon tour de regarder comment se comporte l’application mobile.
Analyse de paquet
En général quand je cherche à avoir des infos sur une API, je regarde comment l’application mobile fonctionne. Pour ce faire, je me charge de capturer les paquets IP qui sortent de mon téléphone et je regarde ce qui concerne l’application.
Auparavant j’utilisais BitShark, une application de capture de flux IP qui me permettait de générer un fichier .pcap que j’ouvrais ensuite dans Wireshark. Ca marche mais c’est vite chiant de devoir transférer les .pcap sur un ordinateur pour ensuite faire l’analyse. De plus, cette application ne semble plus être dans le store Android.
En fouinant le store je tombe sur PCAPRemote qui a un fonctionnement très basique: il permet de faire de la capture de packet en utilisant sshDump.
SSHDump ? Kézako ?
Sshdump va nous permettre de capturer des paquets non pas depuis notre propre machine mais depuis une machine hôte, en l’occurence mon téléphone.
Le téléphone fait office de serveur et mon wireshark de client, fini les envoies de fichier .pcap d’un device à un autre  !
!
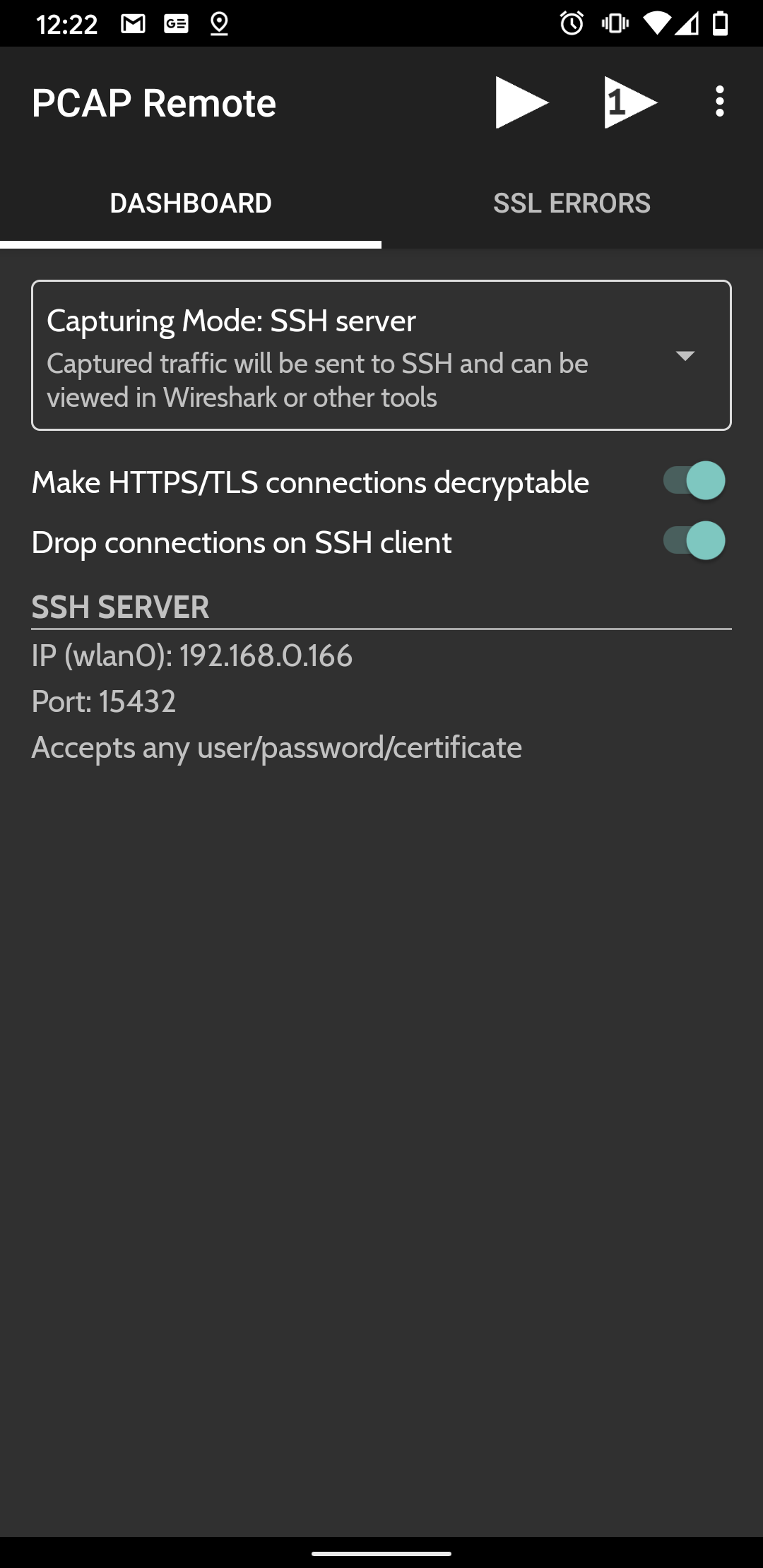
L’interface est assez simple, le bouton “play” permet de lancer une capture global du smartphone tandis que le bouton “Play 1” permet de choisir une application spécifique. Pratique pour éviter de filtrer à posteriori sur Wireshark !
Il suffit ensuite de renseigner l’ip et port de l’hôte (le téléphone) sur wireshark en utilisant l’option SSH remote capture: sshdump
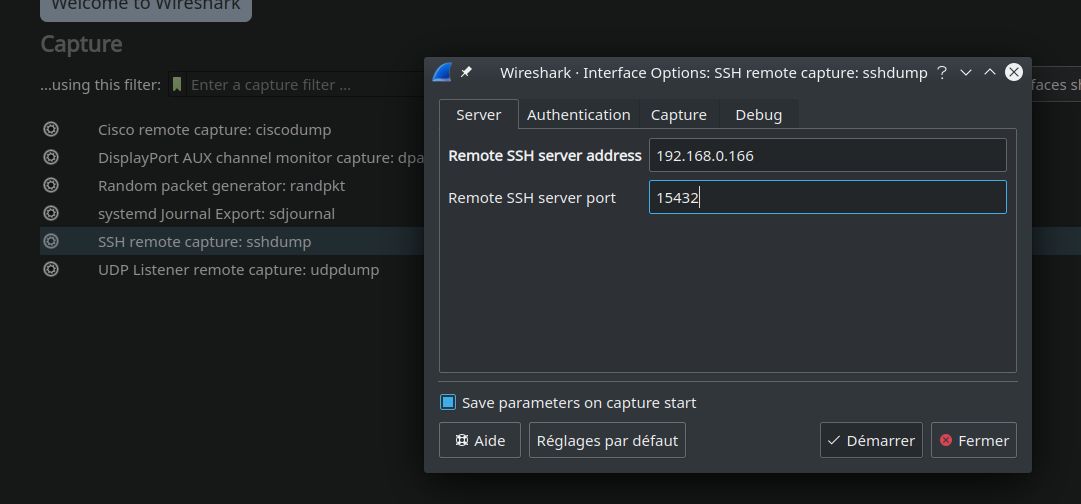
Wireshark reçoit désormais les trames IP, j’en profite pour filtrer sur le protocole HTTP afin d’éviter d’être flooder de requêtes inutiles. Pendant que mon Wireshark tourne, je manipule un peu l’application allociné afin du générer du traffic, je recherche, click sur des films, change de pages etc.
Et qu’est ce qui apparait dans Wireshark ?
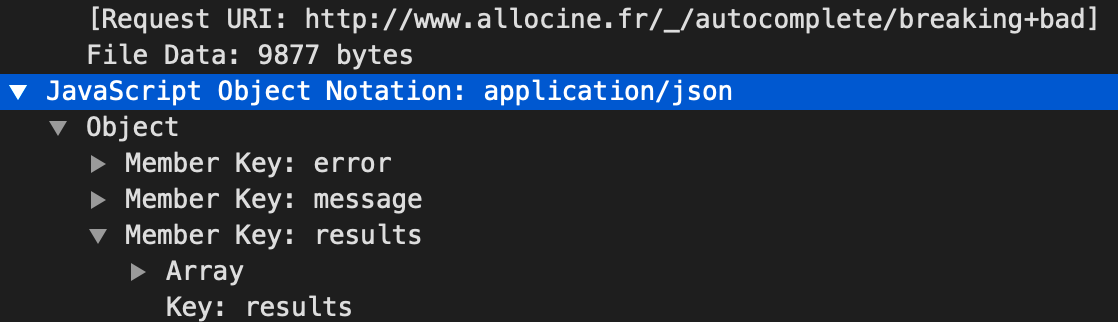
C’est exactement le même endpoint qui était utilisé dans la barre de recherche du site allociné. Dans la capture wireshark je retrouve aussi des appels à des endpoint très similaires de ceux décrit dans l’article de Gromez mais qui ne m’apporte pas les informations que je désire.
A l’exception d’un, qui lui est intéressant:
Ce endpoint contient les scores dont j’ai besoin et le lien de la fiche du film ou de la série, c’est plutôt pas mal !
Problème: L’URL changera dans le temps, le code partner et sig sont une sorte de credential ou d’identifiant,
c’est un des constats dont faisait l’objet Gromez dans son article.
Plus mon investigation dure, plus je me rend compte que je passe beaucoup de temps sur quelque chose qui sera amené à évoluer avec le temps. Du coup, que faire ? utiliser l’API pour récupérer les data ? scraper la page ? dans les deux cas c’est soumis à modifications dans le futur…
La première release
J’ai finalement pris la décision de commencer le développement de l’extension en partant sur un workflow “simple”:
- ⬇️Netflix: Récupération du nom du film ou de la série depuis le DOM
- ⬇️Allociné: Récupération de l’ID et du type (série ou film) depuis le call API de la barre de recherche. Il est à noter qu’au moment où je récupère le nom de la vidéo sur Netflix, je n’ai pas de call XHR ou d’information dans le DOM qui me permet de récupèrer le type de la vidéo (film/série).
- ⬇️Allociné: Récupération de la note en visitant la fiche du film/série (scraping simple)
- ⬇️NoteFlix: Création du DOM avec le score Allociné sous forme de pourcentage et insertion de l’objet DOM dans la page Netflix.
Le workflow fonctionne mais une chose me tracasse… J’ai besoin de connaitre le comportement de l’utilisateur sur Netflix afin de récupérer le DOM qui contient le nom de la vidéo. Si je click sur une vidéo, je veux que le programme cherche la note allociné liée à cette vidéo, pas toutes celles de la page.
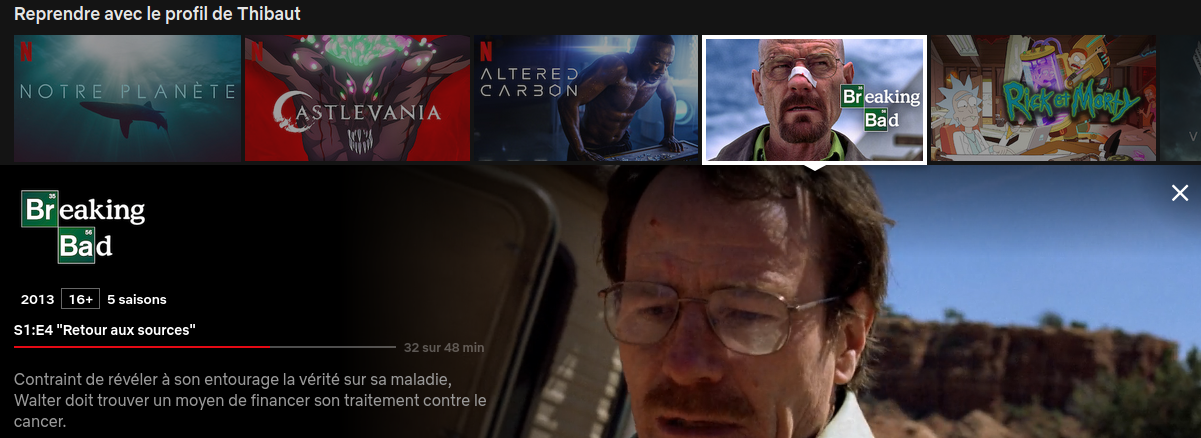
Il y a plusieurs façon de voir les informations d’une série ou d’un film sur Netflix
En naviguant sur le “board” Netflix
Ou en allant directement sur la fiche descriptive de la vidéo
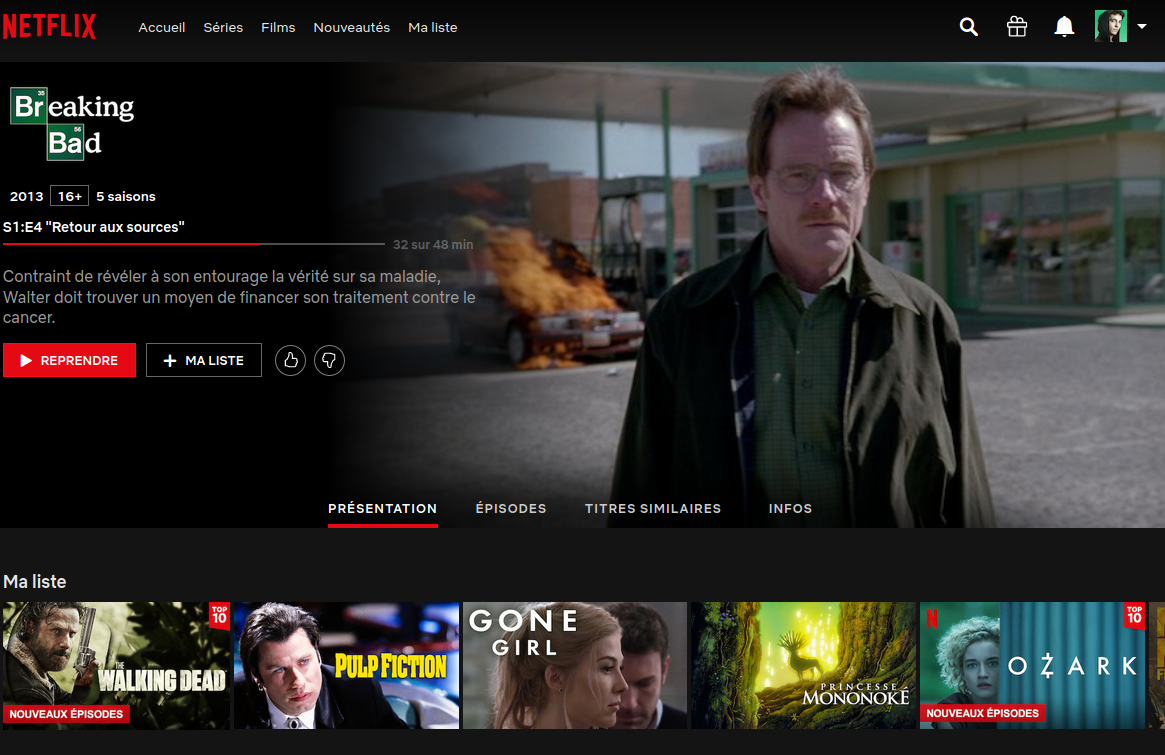
La question à se poser est donc: Comment déclencher la récupération de la note en fonction du comportement de l’utilisateur ? Qu’il charge une page ou qu’il click sur une vidéo, le code devra être déclenché à ce moment là.
MutationObserver
La première idée qui me vient à l’esprit est d’utiliser le MutationObserver.
Le MutationObserver a pour but d’envoyer des évènements dès que le DOM de la page est modifié.
Ce qui donnerait quelque chose du genre:
// Configuration de l'observer
const observerConfig = {
childList: true, // Déclenchera un événement si un enfant du noeud est ajouté ou supprimé
subtree: true, // Déclenchera un évènement si les noeuds enfant sont aussi à observer
attributes: false,
characterData: false,
};
const findRatings = mutationsList => {
// Cette fonction est appelée uniquement quand un évènement est déclenché par le MutationObserver
}
const observer = new MutationObserver(findRatings); // On lui passe la fonction à appeler quand les évènements se délenchent
observer.observe(document, observerConfig); // On lui dit d'écouter sur l'objet 'document' (en gros toute la page)
Parfait, on a notre MutationObserver de prêt, il va nous envoyer des évènements pour déclencher notre code mais il y a toujours quelque chose qui ne va pas… Netflix est développé avec React, la page est donc dynamique et va changer très souvent. Le risque ? Une surcharge d’évènements ! Si on écoute toutes les modifications du document, on va vite se retrouver avec des évènements déclenchés alors qu’ils ne nous seront d’aucune utilité. Par exemple si je glisse ma souris sur mon avatar, un menu apparaitra et un évènement sera déclenché alors que j’aimerais n’avoir que les évènement qui touche aux vidéos.
Peaufinons un peu notre MutationObserver:
observer.observe(document.querySelector('[role=main]'), observerConfig);
On a donc restreint l’observer à n’écouter que ce qu’il se passe dans le bloc principal de Netflix (celui qui contient toutes les vidéos).
En plus de restreindre l’observer à écouter un noeud DOM spécifique, on va aussi devoir filtrer sur les évènements reçus.
Voyons pourquoi avec une illustration simple:
<div role="main">
<div class="video"></div>
<div class="video"></div>
<div class="video"></div>
<div class="helper"></div>
<div class="footer"></div>
</div>
En écoutant div[role=main] l’observer enverra des évènements pour chaque ajout/suppression/modifications de ses enfants.
Si une des div.video change, un évènement sera déclenché et de même pour div.helper ou div.footer alors qu’ils ne nous intéressent pas.
Quand le MutationObserver est déclenché, il renvoie une liste de MutationRecord. On peut donc encore un peu plus affiner notre code afin qu’il n’accepte que les évènements issus de noeuds qui nous intéressent:
const findRatings = mutationsList => {
// Cette fonction est appelée uniquement quand un évènement est déclenché par le MutationObserver
for (const mutationRecord of mutationsList) {
if (mutationRecord.target.classList.contains('video')) {
// Do something ...
}
}
}
Le cache
Maintenant que le code se déclenche bien au bon moment je me confronte à un autre problème, celui des appels multiples à allociné. Chaque fois que la page est modifiée je vais devoir appeler Allociné pour récupérer les informations de la vidéo, un appel HTTP pouvant prendre du temps, ne serait-ce pas judicieux de faire un système de cache ? Je pourrais y stocker les informations et rating liées aux vidéos, si le cache contient la donnée je l’affiche directement et sinon je demande à Allociné l’information.
Il y a plusieurs moyens de gérer un cache coté navigateur, on peut:
- Créer une classe javascript très basique qui s’occuperait de garder les données en mémoire.
- Créer un cookie
- Utiliser le localStorage
- Utiliser le sessionStorage
Le Cookie étant généralement utilisé pour contenir de l’information qui sera ensuite envoyer au serveur (sessionID, authentification etc.) et n’ayant aucun serveur pour NoteFlix, nous pouvons l’évincer d’office.
LocalStorage nous permet de stocker de la donnée qui perdurera dans le temps, si on coupe et relance son navigateur, le localStorage sera toujours à l’état avant fermeture du navigateur.
Il pourrait convenir à notre besoin mais il faudrait prendre en compte le fait qu’entre chaque version de l’extension, la donnée qui est en cache coté client peut potentiellement être au format de versions antérieurs.
Si le model du cache change, il va falloir le purger ou gérer des migrations, un sytème de rétention etc.. ca risque d’ajouter une complexité supplémentaire pour une première version.
Il nous reste donc la création d’une classe et l’utilisation de SessionStorage. Pour la première release de l’extension je suis parti sur une classe simple puis j’ai rapidement modifiée cette classe pour qu’elle se charge de déléguer la sauvegarde des données au SessionStorage.
Le SessionStorage n’acceptant que du clé-valeur, ma classe ne se charge que de serializer/désérializer en JSON, voilà comment ca se présente:
import * as md5 from 'blueimp-md5';
export default class Cache {
constructor() {
this.prefix = 'noteflix_';
}
save(videoInfo) {
videoInfo.hashId = md5(videoInfo.name);
sessionStorage.setItem(this.prefix + videoInfo.hashId, JSON.stringify(videoInfo));
return videoInfo;
}
get(videoName) {
const hashId = md5(videoName);
return JSON.parse(sessionStorage.getItem(this.prefix + hashId));
}
exists(videoName) {
const hashId = md5(videoName);
return sessionStorage.getItem(this.prefix + hashId);
}
}
Le verdict
Une fois toute la logique réalisée, j’ai publié l’extension sur le store de Firefox puis j’ai rapidement remarqué que le MutationObserver posait problème. Parfois l’extension se retrouvait à recevoir 2 ou 3 évènements simultanées pour le même noeud DOM, ou parfois elle ne recevait aucun évènement, du coup elle n’affichait rien.
Pas top pour un utilisateur qui s’attend à avoir un score d’affiché …
J’ai donc décidé de retirer le MutationObserver le temps de trouver une solution plus propre et de passer par un simple setInterval
import Manager from './dom/Manager';
const manager = new Manager();
setInterval(() => {
manager.refreshRatings();
}, 2000);
L’avantage de passer par setInterval, c’est qu’on ne soucis plus de la modification du DOM (donc du code en moins).
L’inconvénient c’est que toutes les 2 secondes une partie du code est executée pour vérifier si l’on doit chercher la note allociné ou non.
Le contrat est rempli, l’extension fait plutôt bien son job 🎉
J’ai encore quelques nice-to-have à intégrer à l’extension comme par exemple le fait de récupérer le rating allociné directement depuis les données structurées:

Ce qui m’éviterait de récupérer la note en scrapant la page.
J’envisage aussi de porter l’extension sur Chrome parceque tout le monde n’utilise pas firefox…
Liens
Un gars qui code, enfin ça c'était avant.